
pi-context:一个让 AI 自己管记忆的小工具
pi-context:一个让 AI 自己管记忆的小工具
我一直在想这件事
用 Claude Code 久了,你会发现一个规律:前三十分钟最顺,之后越来越钝,到了某个点它会突然”失忆”——早期反复强调的规则不见了,开始问一些明明之前已经答过的问题。
后来知道这叫 compaction。上下文快到 95% 的时候,Claude Code 会把整段历史丢给模型做摘要,然后用摘要替换原始对话。有人跟踪过这个过程:一个跑了 200 分钟的 Agent,压缩完后把最初的访问控制规则忘了——那些规则不在系统提示里,而在对话早期,被当成了可丢弃的细节。
compaction 优化的是”接下来该做什么”,不是”为什么这么做”。决策上下文是压缩的第一批牺牲品。
这件事让我不舒服的地方在于:Agent 对这一切毫无感知。它不知道自己正在膨胀,不知道哪些是噪音,更不知道压缩什么时候来。它就像一个只能 malloc 不能 free 的程序,等着操作系统替它做一次全身麻醉的脑叶切除。
我要的不是更大的窗口。我要的是 Agent 知道自己什么时候该清内存,以及清哪一部分。
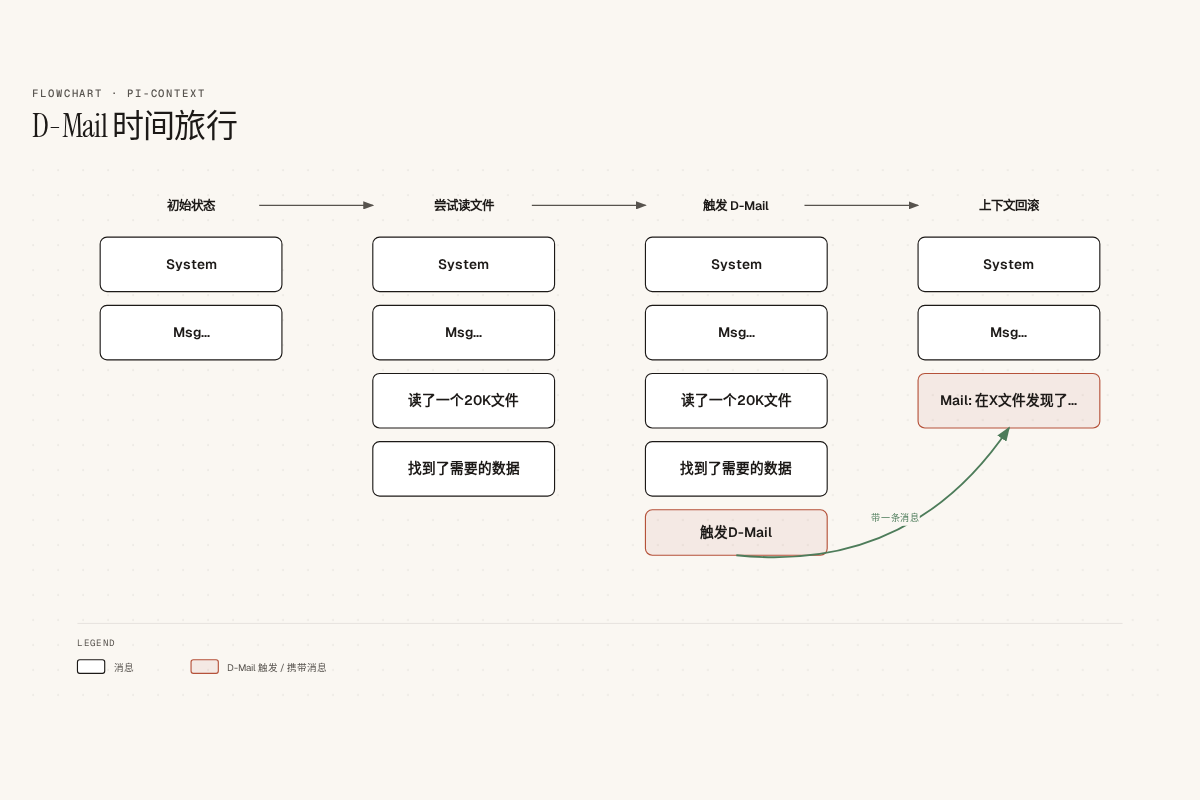
后来我在 Kimi CLI 上看到了 d-mail。名字来自《命运石之门》,功能也像时间旅行:Agent 读了一个大文件,发现只有三行有用,就调用 SendDMail 回滚到”读文件之前”的 checkpoint,带一条消息告诉过去的自己:“我读了 error.log,根因是 DB 连接池耗尽。”
这是个精妙的机制。但用它的人很快会发现一个问题:Agent 能”回到过去”,但它不知道自己在哪里。没有一个地图告诉它”我现在在时间线的哪个位置""我可以跳回哪些 checkpoint”。d-mail 给了 Agent 一辆时间机器,但没给导航仪。
然后我看到了 pi-context
那阵子在翻 Pi Agent 的扩展生态。Pi 是 Mario Zechner 写的一个极简编码 Agent,session 设计很有意思——存储不是线性数组,是一棵树,每个消息是一个节点,通过 id/parentId 链接。Pi 提供了 /tree 命令让人类跳转,但 Agent 看不到这棵树。
有一天在 GitHub 上翻到 pi-context,作者是 ttttmr。README 说实现了”Agentic Context Management”——让 AI 主动管理自己的上下文。
打开源码。代码非常少,核心只有四个文件:
src/ index.ts # 扩展入口 context.ts # /context 命令的 Token 仪表盘 utils.ts # 辅助函数skills/ context-management/SKILL.md # Agent 使用指南读完之后,我发现它解决了一个我一直很在意但没人做好的问题。
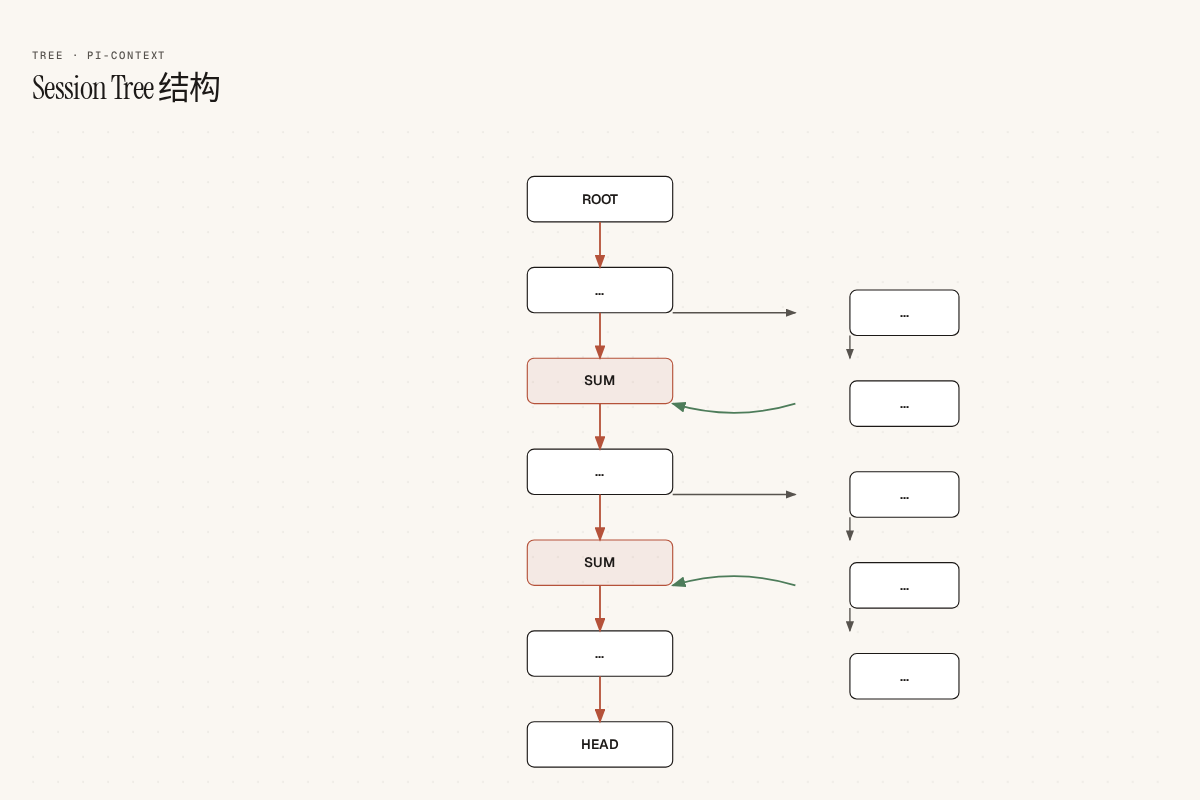
发现一:Session Tree 被翻译成了 Git
看到 Pi 的 tree 结构,第一反应就是:这和 git 太像了。
- 每条消息都是一个 commit
- 跳转到任意节点就是
git checkout - 把一堆探索性的对话压缩成 summary,像 squash merge
pi-context 的作者把这个直觉变成了可执行的设计。给 Agent 三个工具:
context_tag:git tag,标记节点context_log:git log,查看上下文骨架context_checkout:git checkout,在骨架上跳转
Agent 不需要懂 Pi 内部复杂的树结构。只需要三个操作:打标签、看地图、做跳转。
但有个工程问题:对话多了之后 tree 会非常巨大。让 Agent 直接看完整 tree,它的上下文会先被 tree 本身撑爆。所以必须精简。
pi-context 的解法是只展示骨架。通过一个 isInteresting 函数过滤,只保留五类节点:
- ROOT / HEAD(起点和当前位置)
- Tags(Agent 主动标记的里程碑)
- Summaries(压缩归档点)
- Branch Points(发生分支决策的关键路口)
- User Messages(用户的原始输入,天然的任务边界)
中间所有的思考过程、工具调用、内部操作都被折叠。Agent 看到的不是流水账,是一份带书签的目录。
35d4182f (ROOT)ba87607d USER: 排查超时a8e58e1d AI: 读取了日志37ac65e1 TOOL: cat error.log36c8ea0b SUM: 根因是DB连接池耗尽... <- 类似一个 squash commit236d45e1 USER: 准备修复a8e58e1d (HEAD) AI: 方案如下...Agent 决定跳转的时候,就是 git checkout,带一个消息:
context_checkout("36c8ea0b", "已确认根因是连接池耗尽,推荐增加到50...")这个设计让我意识到,上下文管理的本质不是”压缩”,而是降维——把高维的完整对话历史降维到低维的”里程碑空间”,让 Agent 能在不丢失方向感的情况下管理记忆。
发现二:HUD 比地图更重要
context_log 输出时前置了一个 HUD:
[Context Dashboard]• Context Usage: 62.3% (124.6k/200.0k)• Segment Size: 12 steps since last tag 'auth-jwt-start'---------------------------------------------------Context Usage 告诉 Agent 内存压力。Segment Size 告诉它距离上次标记走了多少步。
这个设计很聪明。Agent 不需要理解”信息密度”是什么,它只需要知道”12 步没标记”意味着该行动了。HUD 把抽象的”上下文健康度”变成了两个可以比较的具体数字。
但让我更感兴趣的是 HUD 背后的设计哲学。pi-context 在 before_agent_start 钩子中向系统提示追加了一段指令:
use context-management skillProactively manage session history with context_tag, context_log, and context_checkout.When history becomes noisy, squash it into a precise carryover summary instead of dragging failed attempts forward.这段指令不做 API 说明,而是把上下文管理的心智模型写进了 Agent 的行为准则。Agent 被明确告知:你有责任主动管理历史,噪音出现时压缩它,别把失败的尝试拖向未来。
这是一种”认知脚手架”——不是给 Agent 工具,而是教 Agent 建立空间认知:在哪里→要去哪里→怎么去。
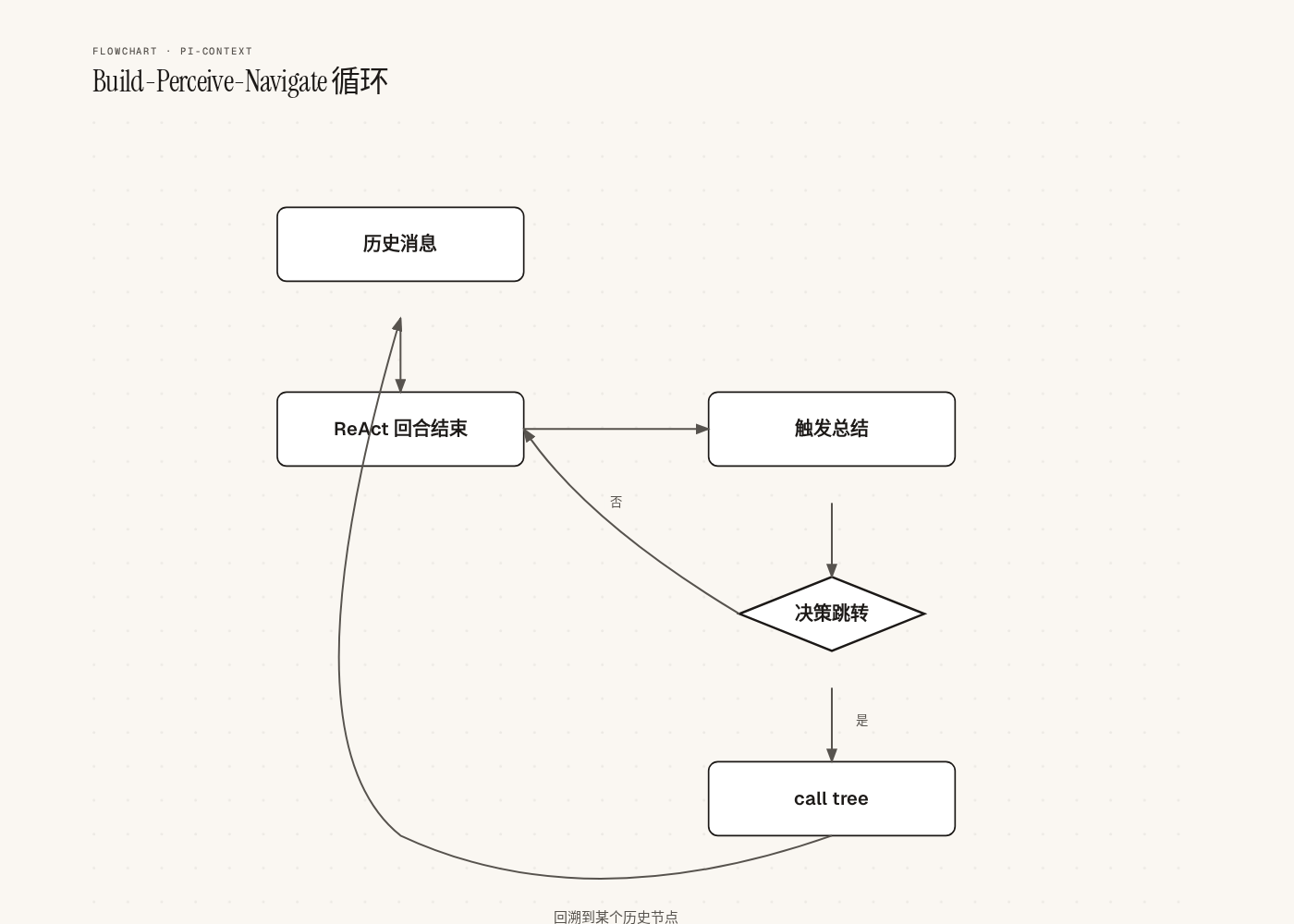
发现三:时间旅行的三段式状态机
context_checkout 是整个系统最复杂的部分。读源码时注意到,实现横跨了 Pi 的三个生命周期事件:
// 1. 工具调用阶段:同步创建新分支async execute(_id, params, ...) { const nid = await sm.branchWithSummary(tid, enrichedMessage); CheckoutParams = { ...params, nid, tid, enrichedMessage }; return { content: [{ type: "text", text: "checkout start" }] };}
// 2. turn_end 阶段:abort 当前回合pi.on("turn_end", async (event, ctx) => { if (!CheckoutParams) return; ctx.abort();});
// 3. agent_end 阶段:执行真正的树导航pi.on("agent_end", async (_event, ctx) => { if (!CheckoutParams) return; if (CommandCtx) { await CommandCtx.navigateTree(CheckoutParams.nid, { summarize: false }); } CheckoutParams = null;});Pi 的会话管理不允许在工具执行过程中直接改变当前分支。所以必须把”创建分支”和”切换 HEAD”拆成两个不同生命周期的事件。turn_end 的 abort 确保旧上下文不会继续输出污染新状态。
这是一个跨生命周期的分布式状态机。三个事件之间通过模块级变量 CheckoutParams 传递状态——在正常的工程实践里,这种方式看起来有点粗糙。但考虑到 Pi Extension API 的限制,这可能是当时最简洁的方案。
另一个印象深刻的细节是 backupTag:跳转前把当前状态钉上一个标签,原始历史被永久保存在侧枝。Agent 事后如果发现总结里漏掉了关键细节,随时可以 checkout 回去查看。
不是删除,是归档。时间旅行是无损的。
源码里还有一个容易被忽略的细节
context_tag 的自动去噪让我停下来想了一会儿。
如果 Agent 没有指定 target,pi-context 不会盲目标记当前叶子节点,而是回溯找到最后一个”有意义”的节点。具体做法是:跳过内部工具(如 context_log 自己)产生的 ToolResult,跳过只包含内部工具调用的 Assistant 消息。
这个逻辑背后是对 Agent 实际行为的深刻理解:Agent 在决定打标签之前,通常会先调用 context_log 查看当前状态。如果没有这个去噪逻辑,标签会被钉在 context_log 自己的输出上——一个对业务毫无意义的元操作节点。
这种”自动跳过噪音”的设计,说明作者不只是写了一个工具,而是观察了 Agent 的行为模式之后做的优化。
双向时间旅行
d-mail 是”回到过去”。但 Session Tree 天然支持双向跳转:每个 SUM 节点都标记了来源,可以从归档的总结再跳回原始分支,也可以从原始分支跳转到另一个未来。
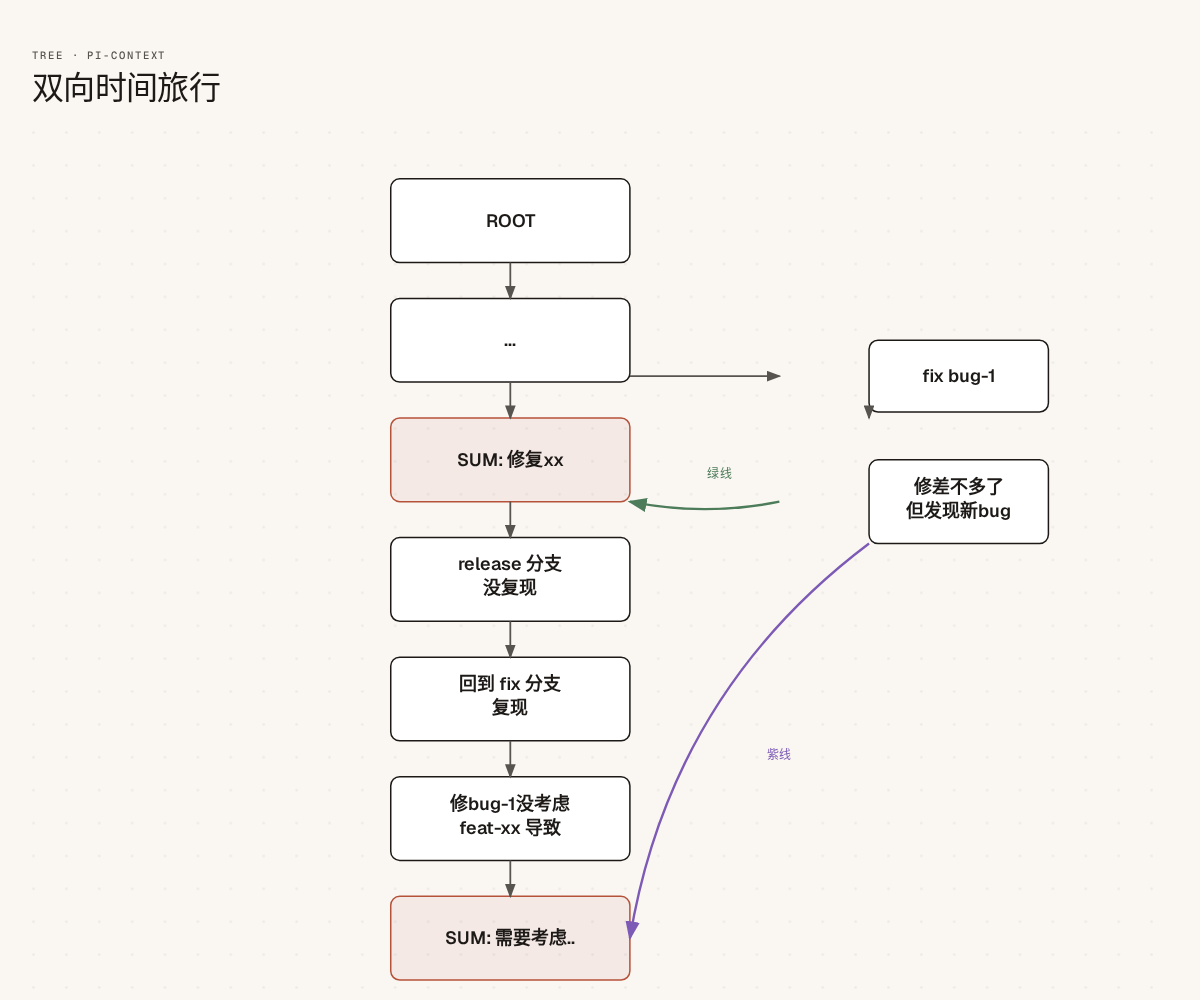
这张图模拟了一个修 bug 场景。Agent 在主线 fork 出 fix bug-1 分支,修到一半发现新问题。把分支总结为 SUM: 修复xx 合并回主线,继续走向 release。但 release 上没复现,Agent 又 checkout 回 fix 分支深入排查,最终发现 bug 和某个 feat 有关,生成新的总结。
绿线是”回到过去”——从侧枝合并回主线。紫线是”前往未来”——从侧枝直接生成新的主线节点。只要分支不被垃圾回收,Agent 随时可以在树的空间里自由移动。
session tree 还有个好处:只要不是太久远的分支,都在缓存里。
读完源码后的一些想法
上下文管理会不会成为 Agent 的”内存管理单元”(MMU)?
现在的 Agent 就像一个没有 MMU 的程序——所有内存 flat 映射,没有分页,没有换入换出。pi-context 做的不是增加内存容量,而是给 Agent 提供了分页和换页的能力。这会不会是未来 Agent 架构的一个标准组件?
Session Tree 是不是一种可操作的长期记忆?
如果把一个 Agent 的所有会话都挂载在一棵巨大的 Session Tree 上,持续通过 summary 把重要内容保留在主线,不重要的内容稀释到久远分支——这本质上就是一种涌现式的长期记忆。重要信息被自然筛选,不重要信息被遗忘,但并未真正删除,只是检索成本变高。
主线 = 工作记忆,侧枝 = 长期记忆。
和 Git 的同步回溯
如果 context_tag 和 context_checkout 能搭配对应的 Git 操作,代码状态和上下文状态可以实现原子级同步回溯。Agent 驱动的重构和实验将拥有真正的 Undo——不是撤销最后一步,而是撤销整个思维过程。
一些不足
context_log的 HUD 只显示百分比和步数,如果能显示”最近 N 条消息的平均 token 长度”或”工具调用密度”,Agent 可以更精确地判断信息密度。- checkout 后的 summary 是一次无缓存的全量历史调用。如果在每次 ReAct 循环都触发,成本会很高。也许可以在 session 内缓存,或者引入更智能的触发策略。
- 目前没有”召回”工具——Agent 需要找回某个被归档的具体细节时,只能 checkout 回 backup tag。一个只读的消息召回工具可能会更有用。
最后
pi-context 的代码不到 600 行,但它触及了一个根本问题:当 Agent 变得越来越长命、越来越复杂,谁来管理它的记忆?
传统的答案是”框架帮它压缩”或”人类帮它切换”。pi-context 的答案是:让 Agent 像管理代码一样管理自己的上下文——打标签、看日志、做 Checkout、写提交信息。
我不知道这个方案在实际业务中能带来多大提升。但从源码设计的精巧程度来看,作者 ttttmr 不仅写了一个工具,而是提出了一种新的范式。这个范式值得被更多人注意到。
https://github.com/ttttmr/pi-context
作者的设计思路原文 https://blog.xlab.app/p/6a966aeb/