在 RAG 和 Agentic 搜索下做结果融合的一些思路
前言:读 EverMemOS 项目源码时发现里面用了 Reciprocal Rank Fusion(RRF),详细了解后意识到它本质上是一类通用的排序融合方法,在 Hybrid 搜索场景下被广泛采用。本文不展开 EverMemOS 本身,而是借这个契机,单独从 RAG / Agentic 搜索的角度,把多通道结果在融合层如何合成一个统一排序这件事梳理清楚。
1. 为什么在 RAG / Agentic 搜索下需要 Hybrid?
在真实业务中,单一路径的检索往往难以覆盖所有信息需求,尤其是在 RAG 和 Agentic Search 这类对检索质量高度敏感的系统里更是如此。以用户画像、对话记忆、知识问答等场景为例,我们往往需要同时依赖几种通道:关键词检索负责捕捉原话里的特定词语,向量检索更擅长语义近邻,图检索能揭示实体和实体之间的关系,结构化检索则对表格、数据库中那些字段化的信息更有效。
这些通道各自擅长的是不同类型的相关性:有的更看重字面匹配,有的更看重语义相似,有的更强调上下文和结构。如果只选择其中一种,很容易出现两个极端:要么重要信息根本没有被召回,要么召回了一大堆噪声,排序结果非常不稳定。
在实际系统中,随着业务发展,查询的形态会不断演化:从短句关键词,到含有上下文的长问题,再到多轮对话中的追问和反问。对于 RAG 和 Agentic 搜索来说,这直接表现为:有些问题更依赖关键词的精确命中,有些问题更依赖语义近邻,还有一些问题只有在理解实体关系或结构化字段后才能被合理回答。Hybrid 搜索存在的意义,就是在召回阶段引入多视角,在融合阶段把这些视角下得到的结果汇总成一个相对稳定的排序,让上层的 LLM 或 Agent 不必在碎片化的多路结果上再做一次检索工作。
下面先给出一个简化的架构视图,用来说明召回与融合的分工,然后重点展开融合层可以采用的几种技术路径。
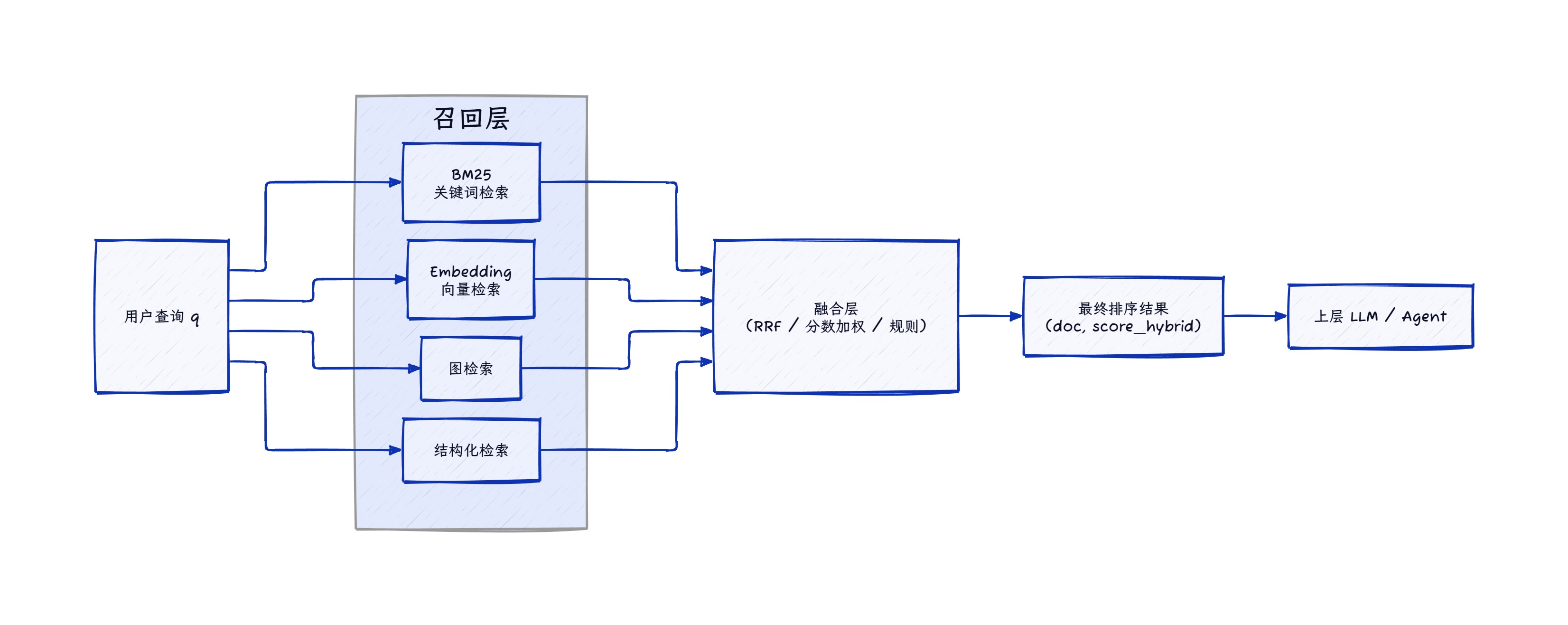
2. 整体架构:召回与融合
在实践中,大家常用的描述是召回 → 融合 → 重排的三层结构。为了把注意力集中在融合层上,可以先把重排暂时放在一边,只保留前两层:召回层负责把各个通道的候选拉齐到桌面上,融合层负责给这一堆候选排出一个大家都能接受的顺序。
如果把整个过程压缩成几步,大致可以理解为:给定一个查询
下面先简要看一下召回层的设计要点,然后把主要篇幅留给融合层的方法与理论。
3. 召回层:多通道设计与配额控制
召回层的目标不是把顺序排好,而是尽量不漏掉潜在相关的文档。典型的设计要点包括:
- 通道选择:根据业务场景选择 BM25、Embedding、图搜索、结构化检索等通道;
- 配额控制(budgeting) :为每个通道分配 Top-K 配额,例如 BM25 取 100 条、Embedding 取 200 条、图搜索取 50 条;
- 基础去重:在单通道内部做简单去重(按文档 ID);
- 召回结果结构化:统一整理为
{doc_id, score, source}的形式,保留通道来源信息。
在这一层,我们通常不会对分数之间的可比性做过多要求,只需要保证:
- 每条通道内部的排序是可靠的(分数单调对应名次);
- 结果集的规模在可控范围内,方便后续融合和重排。
在实践中,召回层还有几个容易被忽视但很关键的问题:
配额分配是策略问题而不是纯参数问题:不同通道的 Top-K 配额不仅影响召回率,也直接影响后续融合的话语权。例如给 BM25 只 20 条、给向量 500 条,几乎等价于把主导权交给向量通道。
静态配额 vs 动态配额:
- 静态配额实现简单,但对不同 query 形态的适配性有限;
- 动态配额可以基于 query 特征(长度、是否包含实体、是否是导航型等)调整不同通道的配额,更适合复杂业务,但需要更多监控与调参。
候选池大小与下游成本:召回过多会放大后续融合和重排的成本和延迟;召回过少则会直接限制上限。通常需要结合性能预算设定一个全局候选池上限,并按通道、按业务重要性进行切分。
4. 融合层:几种混合技术
在融合层,我们的目标是把多通道召回得到的候选集合,转化为一个在全局上可比较的排序结果。常见的技术路径大致可以归为三类:
4.1 分数归一化与线性加权
这是一种最直观的方式。直接在分数空间里做融合,尝试将各通道的分数拉到同一量纲上,再做加权合成:
对每个通道,先做一次归一化,例如:
- min-max 归一化;
- z-score 归一化;
- 基于排序的分位数映射(如将分数映射到
然后对同一文档来自不同通道的归一化分数求和或加权求和,例如:
其中
这一类方法的优点是:
- 实现简单、直观;
- 能够利用分数幅度的信息,例如特别高的得分。
但在工程上会遇到一些明显问题:
- 分数分布差异大:不同通道分数的尺度和分布差异明显,归一化方式容易影响结果;
- 分布随时间漂移:模型或索引配置变化后,分数分布可能随时间漂移,导致线下调好的权重在新场景失效;
- 权重难以泛化:在缺乏标注数据时,
因此,分数加权更适合作为有标注、有监控情况下的精细优化手段,而不是零标注场景下的首选方案。在有标注的情况下,我们甚至可以把上面的线性形式视为一个简单的模型:
- 以用户是否点击 / 转化作为标签;
- 以各通道的归一化分数
- 用逻辑回归或线性回归学习最优的
这实质上是一种极简版的 Learning to Rank,但特征空间和模型形式都被限定在每通道一维分数这个极小的空间里,适合作为从启发式到学习式融合的过渡形态。
4.2 基于名次的 RRF 及变体
为了规避分数不可比的问题,另一类思路是只看名次,不看具体分数。RRF(Reciprocal Rank Fusion)就是其中应用最广的一种,可以理解为一种带平滑项的倒数名次投票制。
我们只关心文档在每个通道中的名次
其中:
直觉上:
- 靠前的名次贡献更大;
- 靠后的名次贡献迅速衰减;
- 如果某个文档在多个通道中都排在前列,那么它的
与分数加权相比,RRF 的工程优势在于:
- 不依赖原始分数的尺度和分布,只需要排序结果;
- 对极端高分噪声更鲁棒,单通道的异常高分不会轻易压倒其他通道的一致意见;
- 实现简单,适合作为零标注场景下的默认融合技术。
在 RRF 周边,还可以演化出一些变体:
- 调整
- 对不同通道使用不同的权重,例如在求和时乘以
- 将 RRF 得分与部分通道的分数归一化结果再做一次线性加权,形成「名次 + 分数」混合方案。
如果从复杂度角度看,RRF 在工程上也比较友好:
- 设通道数为
- 计算
- 由于只依赖名次,RRF 对于分布漂移的敏感度明显低于分数加权,通常可以作为一个少调参也不容易炸的安全选项。
4.3 规则与级联式 Hybrid
在许多业务场景中,我们还会引入一些显式规则,将通道间的关系设计为「主-辅」结构,而不是完全对等的融合:
- 主通道:例如向量检索,负责提供大部分相关结果;
- 辅通道:例如 BM25 或图搜索,用于弥补主通道在某些问题上的盲区。
典型做法包括:
- 先使用主通道得到 Top-N 结果;
- 对于某些缺失类型(如必须包含特定实体的文档),从辅通道补充若干结果;
- 在融合时给主通道更高的基础优先级,通过规则限定辅通道的插入位置和数量。

这类方案的特点是:
- 可解释性强,便于和业务规则结合;
- 不强行把所有通道完全「拉平」,而是保留一个明确的主干路径。
在工程上,规则与级联式 Hybrid 往往和 RRF / 分数加权组合使用:
- 先按主-辅结构过滤、补充候选集合;
- 再在合并后的候选上应用 RRF 或分数加权进行统一排序。
比起纯算法的融合,规则和级联方案更适合把业务约束显式编码进系统,例如:
- 对安全 / 合规相关的文档设置硬性优先级,不允许被其它通道结果淹没;
- 对某些高价值来源(官方文档、权威百科等)在同等相关性下给予额外加分;
- 在多语言、多区域场景下,通过规则确保结果语言 / 地域与用户匹配。
这些设计通常不适合完全交给模型自动学习,而是需要和产品 / 运营侧共同约定,再通过实验逐步固化到系统中。
4.4 排序聚合视角:RRF 与其它 Rank Fusion
从更抽象的排序聚合(rank aggregation)或社会选择视角看,我们在做的事情是:给定多个排序器输出的序列,构造一个集体排序。这一问题在信息检索与投票理论中都被系统研究过。
经典的几类排序聚合方法包括:
- Borda count:每个排序位置赋予线性递减的分数,例如第 1 名
- Condorcet 家族方法:将排序问题转化为成对比较,寻找在多数意义下更优的一致排序;
- Kemeny optimal 排序:在所有可能的全排序中,找到一个使得与各个输入排序距离之和最小的排序,这个定义在理论上很漂亮,但计算复杂度很高。
RRF 可以看作是一种带有倒数权重核的 Borda 变体:
- 它不是给第
- 平滑常数
- 与 Kemeny 这类需要全局优化的排序不同,RRF 的计算是局部且可加的,只需遍历一次候选集合即可完成。
与其它 rank fusion 方法相比,RRF 还具备两个在理论与实践上都很有用的性质:
- 对单调变换不敏感:由于只依赖名次,任何在单个通道内保持排序不变的分数变换(如对数、缩放)都不会影响最终结果;
- 对共识相关性的显式偏好:只有在多个通道都给出较好名次的文档,才能获得显著更高的得分,这与我们在信息检索中追求的稳定相关结果高度契合。
从更理论的角度看,许多排序聚合方法可以被视为在某种距离度量下逼近 Kemeny 最优排序,即在所有可能的全排序中,寻找一个与各个输入排序距离之和最小的排序。距离常用 Kendall tau,这一度量本质上统计了两个排序之间顺序相反的成对项个数。完全求解 Kemeny 排序是 NP 困难的,因此实际系统往往采用启发式近似。RRF 可以看作是一类强调前几名、一致性导向的启发式,它并不显式最小化某个全局目标,但通过对高名次赋予倒数权重,在直观上偏向那些在多数排序中都靠前的文档,从而在计算复杂度与近似质量之间取得一个工程上可接受的折中。