mem0 源码阅读:一个工程化记忆系统
最近在系统性看各种 Agent Memory 的实现,学习了不少开源项目和论文,打算写一组文章,输出一些记忆文章。这篇文章准备当做系列里的第一篇(实际上 COLMA 那篇才是第一篇),从相对简单但工程化程度比较完整的 mem0 开始。本文主要从工程视角出发。
1. 记忆系统和 RAG
先从基线讲起:如果只用最朴素的 RAG 来给对话做记忆,一般会怎么做?
常见做法大概是:
- 每轮对话结束,把这一轮的文本 append 到某个日志列表里。
- 定期或每轮把日志切块、做 embedding,写进向量库。
- 用户下一次提问时,用 query 去向量库做相似度搜索,把 topK 结果当成上下文拼给模型。
如果我们就把这套东西当成“记忆系统”,很快会撞到几个典型问题。
第一是上下文不连贯。现实里的对话是按话题组织的,话题内部高度相关,话题之间又是突变的;而在向量库里,我们只看到一堆碎片化的 chunk。检索拿回来的内容,往往是同一话题被撕成很多段,顺序也乱了。
第二是碎片化和矛盾共存。比如用户连续几次提到“我喜欢 A”,你一直在追加新条目,最后搜出来全是类似的句子;某个时间点用户改口说“其实我现在不喜欢 A 了”,如果没有 update 机制,只能继续 add,新旧偏好会长期并存,最终哪个被模型用到,完全取决于召回运气。
第三是召回不可控。简单的向量搜索 + topK 很难保证那些真正重要、应该进入长期记忆层的内容一定能被抽出来。
这背后其实是一个定义问题:
- RAG 更像是在 管理原始对话日志 的检索。
- 记忆系统更关心的是 长期稳定的语义事实,比如用户是谁、偏好什么、有什么长期目标。
如果把这两件事混在一起,既不好维护,也不方便审计。实践里更合理的做法,是把它们拆开:上层保留一份短期对话上下文,用来回答当前问题;底下再挂一层长期语义记忆,只存经过整理的事实,并且支持更新和回溯。
mem0 就是站在这个位置上,尝试把这层长期记忆做得更像个系统,而不仅仅是一个 append-only 的向量库。
2. mem0 的目标和定位
从项目本身的定位来看,mem0 算是比较早期、而且工程化程度比较高的一批记忆层开源实现之一。官方 README 里给它的角色很直接:给各种 Agent、聊天机器人和应用提供一层通用的长期记忆服务,可以自托管,也可以用托管平台。
从功能上看,它对外主要暴露一个 Memory 抽象:
- Python/TS SDK 和 REST API 都是围绕
Memory /AsyncMemory这两个类展开; - Memory 底下统一封装了向量库(pgvector、Qdrant 等)、可选的图数据库(Neo4j、Memgraph 等)、LLM、embedding 模型以及一个本地的 history 数据库;
- 对调用方来说,基本就是围绕
add / search / update / delete / history这几个方法来用。
从实现上看,mem0 并没有很复杂的算法,亮点更多在工程完整度和边界控制:Memory 这一层的职责划得比较清楚,下层的向量库、图库、LLM 统一走工厂模式,然后加一个 SQLite 的历史记录。
下面是架构图:
3. mem0 Memory 模块总体结构
从代码结构看,mem0 的入口相当收敛:
- 无论是 REST API 还是 Python / TS SDK,最后都落到
Memory(同步)或者AsyncMemory(异步)这两个类上。 - 这两个类背后,通过工厂模式挂了一整套可插拔组件:embedding 模型、向量库、图数据库、LLM、历史库和遥测。
可以用一张架构图来解释依赖关系:
从调用者的角度看,Memory 层对外只暴露了一组方法:add / search / get / update / delete / history。内部则负责:
- 把 messages 预处理成统一格式。
- 在 add 时,根据配置选择是直接写,还是推理后再写。
- 把所有读写请求都带上 user/agent/run 这些过滤条件,做会话隔离。
- 把每一次变更都记录到 historydb。
在这些方法里,最有意思的是 add(),因为它同时承载了新增、合并、删除三种行为。下面我们单独看 mem0 的流程。
4. add:一个 API 中的多种记忆操作
在 mem0 里,add() 并不被视作插入一条记录这么简单,而是一个记忆管理入口:
- 在最简单的配置下,它只是把消息切成若干条,逐条 embedding,写入向量库;这一支和前面说的朴素 RAG 差别不大,mem0 真正有特点的是
infer=True这条路径。 - 在
infer=True时,它则会调用 LLM 先抽出候选事实,再去对齐已有记忆,最后生成一组 ADD / UPDATE / DELETE / NONE 的操作计划。
借助下面这张流程图来讲解一下 add 的整体路径(对应 mem0/memory/main.py 中 Memory.add 及其私有方法):
下面我们单独看 mem0 的流程。
4.1 infer=False:直接写入的路径
在 infer=False 时,add() 的行为基本等价于「带 metadata 的 RAG 写入」:
- 入口做的第一件事,是通过
_build_filters_and_metadata 构造过滤条件和基础元数据。这里要求调用时至少提供user_id /agent_id /run_id之一,用来区分不同会话或不同 Agent。 -
Memory.add 会把str /dict /list[dict] 这几种形态的 messages 统一规整成[{'role': ..., 'content': ...}],并处理好视觉消息(图片转描述文本)。 - 然后走
_add_to_vector_store(..., infer=False) 这条支路:遍历每条消息(忽略role == system),调用 embedding 模型,把得到的向量连同 payload 一起插入向量库。每一次插入同时在 history 表里写一条event = "ADD"的记录。
这个分支本身没有什么复杂逻辑,但可以看出,哪怕在最朴素的模式下,mem0 也已经把会话隔离和变更记录做成了默认行为,而不是留给调用方自己维护。
4.2 infer=True:LLM 驱动的智能记忆管理
infer=True 是这套设计的核心。它让 add() 具备了「判断要不要记、记成什么样」的能力,大致可分成几个阶段。
第一步是从多轮对话中提炼出候选事实。
Memory.add 会先调用 parse_messages 把一组 messages 压成带 role 的长文本,形如:
system: ...
user: ...
assistant: ...然后根据这是用户记忆还是 Agent 记忆选取不同的 system prompt(也允许自定义 fact 抽取 prompt),调用一次 LLM,请求它输出 JSON 格式的 new_retrieved_facts。每一个 fact 都是模型认为「有长期价值」的一句或几句描述,比如用户在上海工作、用户对辛辣食物敏感之类。
第二步是围绕这些 facts 去找旧记忆。
对每个 fact,再做一次 embedding,并带着刚才构造好的 user/agent/run 过滤条件,去向量库做语义搜索。搜索结果去重后,得到一组 retrieved_old_memory,可以理解为「和本次候选事实相关的历史记忆集合」。
第三步是让 LLM 决定具体操作。
这一步会构造一个结构化的 prompt,把「新事实 + 相关旧记忆」一起给 LLM,同时规定输出格式必须是 JSON,其中每个元素都包含:
-
event:ADD / UPDATE / DELETE / NONE; -
text:新记忆文本(ADD/UPDATE 时使用); - 以及在 UPDATE/DELETE 情况下,指向旧记忆的 id。
这一阶段等于是把「合并还是新增还是删除」的策略交给了 LLM 来做语义判断:
- 如果某个 fact 和已有记忆只是在细节上有补充,就倾向于 UPDATE;
- 如果代表的是全新的信息,就 ADD;
- 如果它明确否定了旧记忆,可能会触发 DELETE;
- 如果模型认为这句话没有长期价值,就给出 NONE。
最后一步是落地这些 actions。
ADD 的情况比较直接:调用 _create_memory 插入向量库,同时在 history 表里写一条 ADD;UPDATE 则需要先从向量库读出旧 payload,构造一个新 payload(保留 created_at 和会话相关字段,只替换 data 和 updated_at),用 update 写回,再记一条 UPDATE 类型的历史记录,里面同时存 old/new 两个版本;DELETE 类似,先 get 出旧内容,之后从向量库删掉,history 里记一条 DELETE 并标记 is_deleted = 1;NONE 则不动向量,只是用 _update_memory_session 之类的方法更新 metadata 里的会话维度。
从整个 pipeline 流程来看,add(infer=True) 的职责可以概括成一句话:在短期对话和长期记忆之间做一次带上下文的筛选与重写,让向量库里存的不是原始聊天,而是已经抽象过的事实集合。
为了方便对照,可以再看一张更概括的流程小图,专门对应 infer=True 模式下的两次 LLM 调用:
这也是为什么在性能上会存在写放大:一次 add 触发了两次 LLM 调用,并且中间还有一轮向量检索。(我测的时候跑的非常慢)
5. search / update / delete:读写路径与边界
相较于 add(),search / update / delete 这几个接口的逻辑就常规得多,但依然延续了会话隔离和 historydb 这两条主线。
5.1 search:只读、无 LLM 的查询
Memory.search 的实现是典型的 embedding + 向量检索,没有在这一步再引入额外的 LLM 调用。它的调用序列大致如下:
可以注意到几点:
- search 只涉及向量库和可选的图库,不触碰 historydb,也不修改任何状态。
- 如果配置了 reranker,会在拿到候选结果后再做一次重排,但依然是纯检索逻辑,不会再去叫 LLM。
- 图搜索和向量搜索是并行分支,最后把结果合在一起。这和那种先向量检索再扩图邻居的 GraphRAG pipeline 不太一样,更偏向两个视角的独立召回。
这部分实现比较克制:它只负责取回可能相关的记忆,至于这些记忆要如何组织成上下文、是否要翻页拿前后文,mem0 没有规定做法,留给上层 Agent 或业务代码处理。
5.2 update / delete:显式操作与历史记录
update 和 delete 的行为可以看作是对 add(infer=True) 里 UPDATE / DELETE 分支的显式版本:
-
update:调用者直接给出 memory_id 和新的 data,Memory 层会做一次 embedding 替换向量,同时读出旧 payload,写入一条event = "UPDATE"的历史记录,保留改前和改后的内容。 -
delete:先从向量库 get 出旧内容,再删除对应向量,最后在历史表记一条DELETE,把旧内容放进old_memory 字段,并打is_deleted = 1。
这两条路径都不再经过 LLM,逻辑相对简单,但和 add(infer=True) 共用同一套 history 机制。
6. historydb:历史日志
historydb 是 mem0 里存在感很强的一个组件,它不负责存向量,也不参与检索,只负责记录某条记忆从创建到修改再到删除的全过程。
表结构用了一张 SQLite 的 history 表,大致包含:
-
memory_id:对应向量库里的那条记忆; -
old_memory /new_memory:某次变更前后的文本内容(ADD 时old_memory 为空,DELETE 时new_memory为空); -
event:ADD / UPDATE / DELETE; -
created_at /updated_at:这条历史记录自身的时间; -
is_deleted:是否代表一条删除记录; -
actor_id /role:是谁触发了这次操作,以及当时的角色(user / assistant)。
这种设计的直接效果是:
- 向量库只保存当前状态,不负责记历史版本;
- 所有「这条记忆经历了什么」的问题,都可以通过
Memory.history(memory_id)查出来。
换一句话说,mem0 把每条记忆当成了一个有限状态机,状态的转换(ADD → UPDATE* → DELETE)全部写进了一张独立的表。这在需要做审计、回滚、可视化的时候,会比覆盖式更新友好得多。
7. 设计和使用上的一些思考
读完这部分代码之后,个人有几点想法。
7.1 mem0 更适合作为长期记忆层
从 add(infer=True) 的设计可以看出,mem0 更偏向长时稳定的语义记忆,而不是每一句话都要写入的日志系统。比如用户只问一句「烤鱼健康吗」,这本身不是 fact,更像是一个即时问题;在这种输入下,LLM 很可能抽不出任何 new_retrieved_facts,最终不会写入记忆。
更典型的情况是几轮对话拼在一起才有意义。比如:
- 第一轮,用户问“烤鱼健康吗”。
- 第二轮,又问“草鱼好吃吗”。
- 聊天上下文里还有一条信息是“今天晚上六点要和同事聚餐”。
人类在这里很容易脑补出一个场景:这个用户大概率在考虑今天晚上要不要吃烤鱼,或者他本身就经常吃这类东西。但在 mem0 现在的实现里,如果你把这几轮拆成一次次 add(infer=True) 调用,模型在每一轮里单独抽事实,很可能认为这几句都不值得记,于是整个片段都进不了长期记忆。这就是我在看代码时感觉比较明显的一点:mem0 的 fact 抽取是一次调用内的,缺少跨多次 add 去拼出一个更大事实的能力。
如果直接把 mem0 接在一个高频群聊后面,每条消息都丢进 add(infer=True),就容易出现两种极端:要么什么都没记住,要么记了一堆看上去像事实、实际上很散、不形成完整画像的句子。
更合理的做法,是在上层再加一层短期工作记忆(也就是常说的 working memory):
- 上层维护最近 N 轮对话,专门用来回答当前轮的问题;
- 只有当某个阶段性话题结束,或者检测到出现了明确的个人偏好、背景信息、长期目标时,才把这一段对话打包交给 mem0;
- mem0 则专注于把这些内容收敛成一组长期事实,并在后续请求里持续维护和更新。
可以用一张概念图来表示这两层之间的关系:
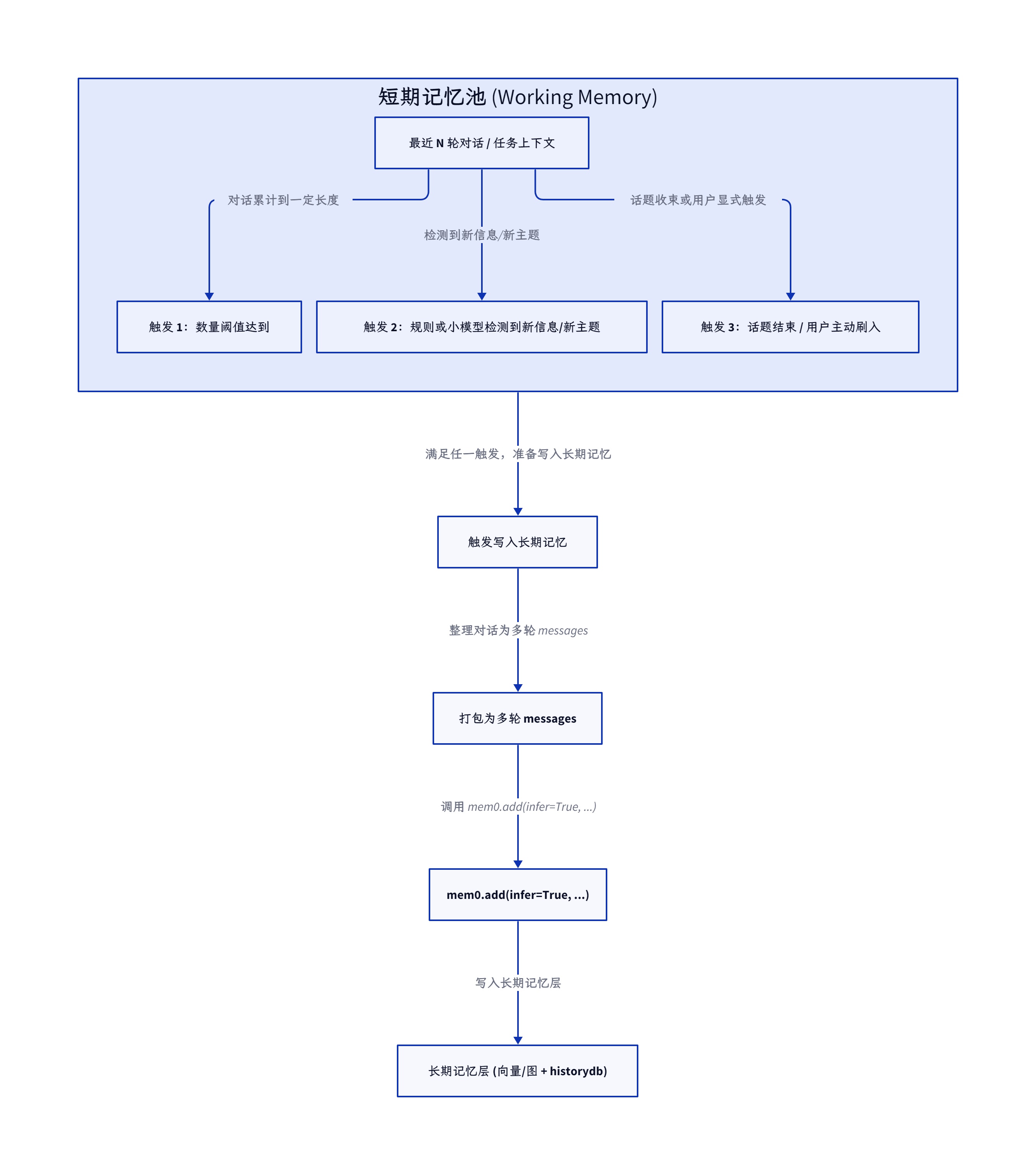
在这种架构下,new_retrieved_facts 更像是从短期工作记忆里抽取出来、准备写入长期记忆的候选事实单元,而不是对所有问题的机械记录。
7.2 写入路径存在明显的写放大
infer=True 这条分支天然带来写放大:一次写入包含两次 LLM 调用和至少一次向量检索。这在低 QPS 的场景下问题不大,但如果想在一个高并发系统里对所有对话都开推理写入,就需要认真评估成本和延迟。
这里可以结合代码简单算一下账:
- 第一次 LLM 调用发生在
get_fact_retrieval_messages,对整理后的整段对话做一次 fact 抽取; - 抽出来的每个 fact 都要走一遍 embedding + VectorStore.search,这一步的复杂度和 fact 个数成正比;
- 第二次 LLM 调用发生在
get_update_memory_messages之后,把新旧记忆一起喂给模型,让它产出 actions; - 最后根据 actions 分别调用
_create_memory、_update_memory、_delete_memory,并同步写 history。
也就是说,一次 add(infer=True),在最坏情况下会有:
- 一次对话级别的 LLM 请求;
- N 次向量检索(N 是抽出的 fact 数量);
- 再加一次新旧记忆对齐的 LLM 请求。
如果你是给单个用户做个人助理,这个开销未必夸张;但如果把 mem0 接在一个高并发入口(比如一个面向大量用户的客服系统)后面,就不太适合每条消息都同步走这条路径。
更现实的用法,是在应用层做两层区分:
- 在线链路只依赖短期上下文 + 既有长期记忆的 search,确保延迟可控;
- 把
add(infer=True)放到后台队列里,按用户或会话做限流,比如每 N 轮对话或每隔一段时间才触发一次。
从这个角度看,mem0 更接近一个「长期记忆整理服务」,而不是写日志那一层。
7.3 记忆操作强依赖 LLM 的语义判断
在 add(infer=True) 里,ADD / UPDATE / DELETE / NONE 的决策完全交给了 LLM。好处是接口非常简洁:调用者只需要给一段对话,不必自己写一堆 if/else 去判断是否重复、是否矛盾。
在代码层面,这部分逻辑主要集中在 get_update_memory_messages 和随后的第二次 llm.generate_response 上:
- 先把刚抽出来的 new facts 和刚刚检索到的旧记忆一起打包成一组 messages,喂给模型;
- 要求模型输出一个 JSON,里面列出每个新记忆对应哪个旧记忆、打算执行什么事件(event)、使用什么新文本;
- 后面执行分支里,只是严格按照这个 JSON 决策去走
_create_memory /_update_memory /_delete_memory,并且顺带写 history。
好处是调用方式非常统一:上层永远只调一个 add(infer=True),所有「要不要记、记成什么样」的问题都丢给 LLM 来裁决。你甚至可以通过换 prompt 或换模型,试着调整它对重复、冲突的敏感程度。
代价则在于:
- 模型可能过度合并,把一些细节在 UPDATE 时压缩掉;
- 也可能不够激进,导致类似内容长期共存;
- fact 的粒度完全由 prompt 和模型行为决定,目前实现里没有额外的 fact 级别约束机制,也没有在代码里做「防御性」检查,比如限定一次更新只能覆盖哪些字段。
这不是 mem0 独有的问题,所有 LLM 驱动的记忆系统都会遇到。mem0 的选择是把这部分逻辑集中到 add(infer=True) 的一条管线上,至少在工程上是透明的:你可以从 prompt、模型版本和 history 记录三个维度去观测和调参。
7.4 检索策略与上层架构
前面提到,mem0 在 search 部分并没有引入很复杂的 GraphRAG 流程,而是保持了向量检索加可选 rerank、可选图检索的组合。这带来的一个结果是:
- 上下文的组织方式完全交给上层决定;
- 如果想要翻页拿前后文、多轮 search 逐步缩小范围,需要在 Agent 或业务代码里自己实现;
- mem0 的职责止步于给你一批可能相关的记忆。
如果不考虑成本,只看怎么把上下文接得更顺,在 mem0 这一层之上大致有两条思路,可以和前面的 search 组合在一起。
第一种是给向量检索结果加一个“翻页”能力。比如拿到某条记忆后,再显式去取它前后若干条,类似现在很多代码 agent 里的 Read 工具,支持 offset / limit:
- 好处是实现简单,不需要额外的 Agent 结构,直接在应用侧包一层就行;
- 坏处是 LLM 一旦走偏,它在翻页过程中看到的一堆无关内容,都会被写进对话上下文里,后面的问题也会继续被这些错误上下文污染,很难「撤销」。
第二种是写一个专门的 search agent。主 Agent 不直接操纵翻页,而是把“我要找什么”丢给一个专门的检索 Sub Agent,让它负责在向量库里多次 search / 翻页,最后只把一小段结果(比如若干条记忆加上它自己的中间判断)返回:
- 好处是主 Agent 看到的是一份已经整理过的结果,过程中的「乱翻页」不会直接污染主对话的历史;
- 而且 search agent 可以用一个相对便宜的模型,反复调用也不至于太贵;
- 坏处是系统结构更复杂一些,需要你自己定义好主 Agent 和 search agent 之间的接口,以及错误时如何回退。
如果想把这条线再拉长一点,可以参考 kimi-cli 那种「给自己发 DMail」的做法(命运石之门梗,DenwaRenji 是啥梗? || DenwaRenji What is the plot?,月之暗面真是个有意思的公司):当你发现一次 search agent 的决策明显是错的时,不是硬着头皮把错上下文往后拖,而是显式给主 Agent 写一条更正消息,相当于在对话历史里打一个“撤销”标记,后面的推理就可以选择性地忽略这一段错误分支。这个思路用在 mem0 上,基本等价于在长期记忆之上再盖一层“可回滚”的检索历史,让系统有机会在犯错之后把自己从错误上下文里拉出来。
8. 总结
整体来看,mem0 在把记忆这件事工程化上做了几件比较关键的事:
- 把
add 设计成一个具备决策能力的入口,在infer=True下通过两次 LLM 调用和一次向量检索,把 ADD / UPDATE / DELETE / NONE 合在一条管线里做完。 - 用一个独立的 SQLite history 表记录所有变更,把每条记忆视作一个可以审计的状态机,也可以说是一种血缘追踪,而不是简单的覆盖式更新。
- 通过Vector Factory 和 Graph Factory,把底层存储细节屏蔽在统一接口之后,让 Memory 层只关心“存什么、怎么搜”。事实上 mem0 的绝大部分代码都在适配十几种向量库和图数据库上。
- 在设计上明确区分了长期记忆和短期工作记忆的角色,前者交给 mem0,后者留给上层框架或应用代码。
不管怎么说,mem0 的源码是值得读一遍的,哪怕最后不直接使用这个库,它在接口设计、读写路径、历史记录这些细节上的处理,也是一份相对完整的参考实现,而且比较简单,读完可以根据自己的场景做一些增强。