对 COLMA 认知分层记忆架构的工程化重构与思考
最近阅读了四川大学团队发表的论文《A Scenario-Driven Cognitive Approach to Next-Generation AI Memory》。论文通过脑科学的分析,指出了当前 AI 记忆系统(主要是 RAG 和向量数据库)存在的“静态性”与“割裂性”问题,并创新性地提出了一种基于认知场景驱动的 COLMA(Cognitive Layered Memory Architecture) 架构。
先读论文
现有的 AI 记忆系统通常被简化为“向量数据库 + 检索算法”的组合。这篇论文通过六维评估(包括动态更新、抗灾难性遗忘、多模态整合等)指出,这种架构本质上是静态的数据堆砌,缺乏人脑的动态适应性。为了突破这一瓶颈,作者没有直接堆砌技术栈,而是采用了反向工程的思路,从脑科学反思人类记忆的模式,并基于此推导出了下一代记忆系统的核心需求。
从脑科学看人类记忆
论文认为,记忆不是单一的存储行为,而是根据不同任务高度动态化的过程:
- 场景一:毒蘑菇识别(感知与生存级反应)
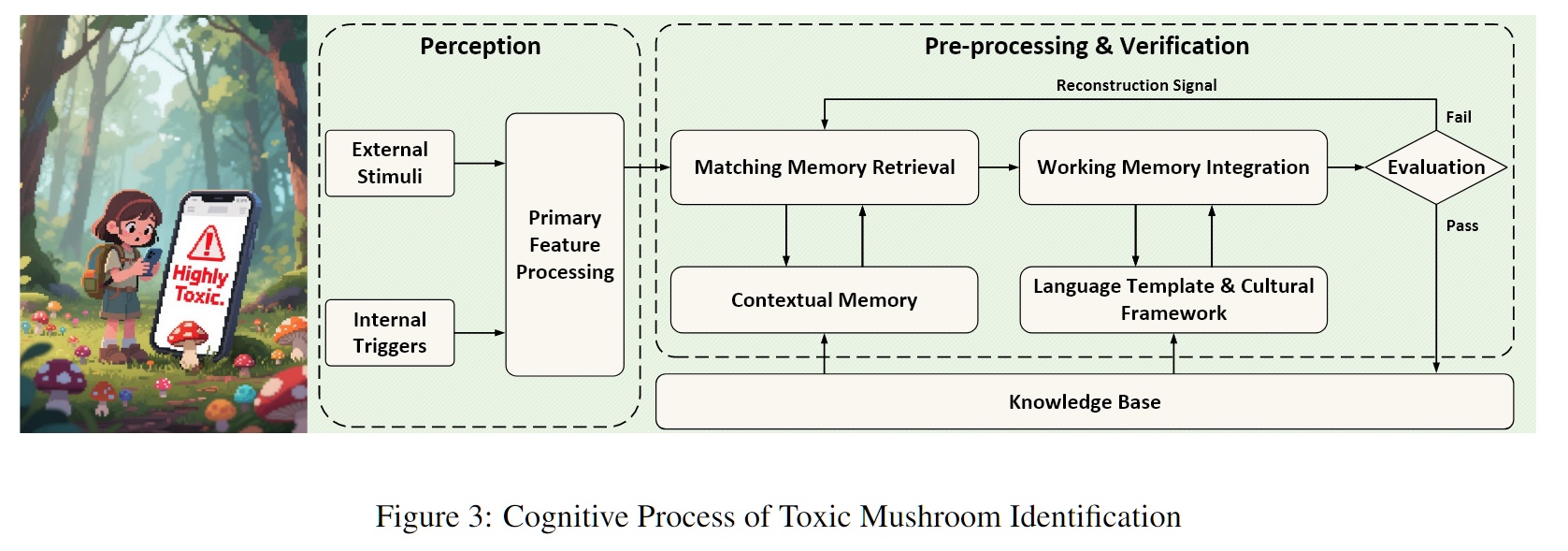
当你由远及近观察一个蘑菇时,你的大脑在毫秒级内整合了颜色、形状(视觉)甚至质感(触觉)。一旦识别出“剧毒”特征,系统会立即触发预警并强行写入长期记忆。
但现有的多模态模型往往将视觉和文本分开存储,且缺乏这种“高优先级写入”的生存机制。因此记忆系统必须具备极低延迟的多模态感知接口和工作记忆集成能力,能够在感知到关键特征时迅速闭环。
- 场景二:日常回忆(动态重构机制)
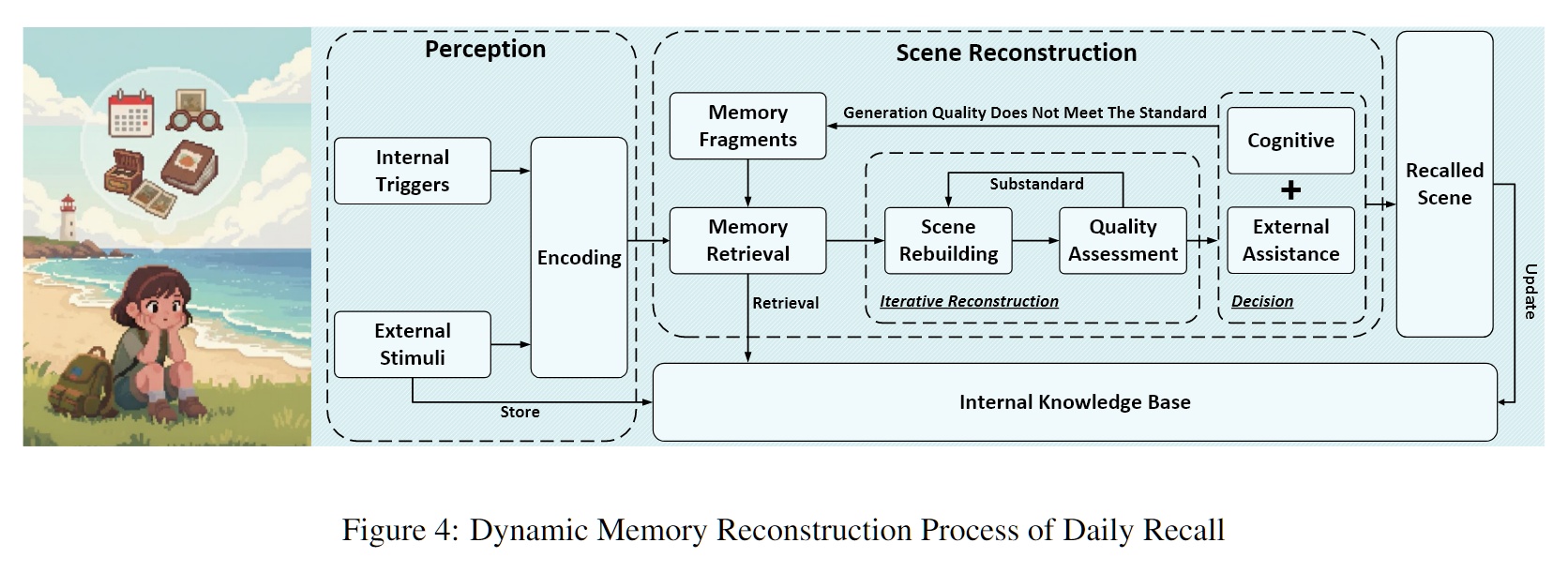
当你试图回忆“上个月2号做了什么”时,你的大脑并没有直接播放一段录像。你首先会锚定时间(“那天是周几?”),检索碎片线索(“好像开了周会”),然后结合外部提示(查看手机照片)进行迭代式重构(Iterative Reconstruction)。如果发现逻辑不通,大脑会自我否决并重新检索。
而目前的 RAG 检索是一次性的 Key-Value 匹配,缺乏“检索-评估-再检索”的自我修正回路。记忆检索应当是一个生成式重建的过程,包含多轮次的自我验证与修补。
- 场景三:数学解题(Mathematical Problem-Solving Process)
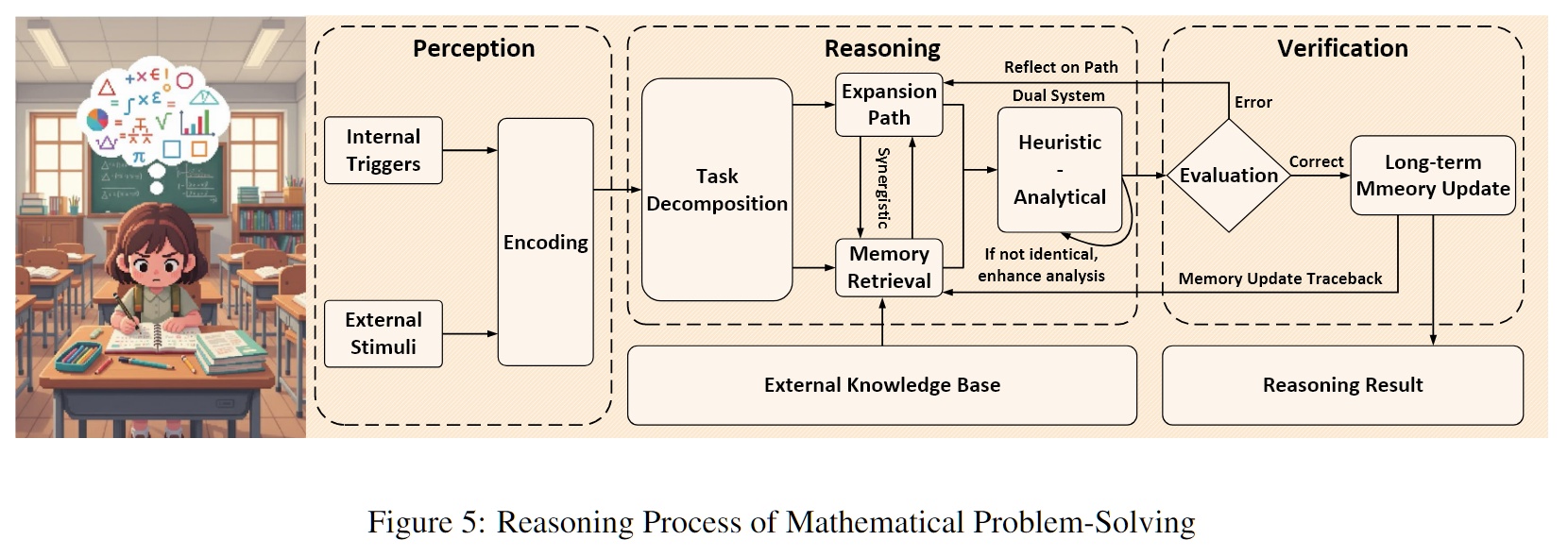
在解决复杂数学题时,人脑通过“系统1”(直觉启发)快速寻找思路,同时利用“系统2”(规则分析)进行严密的逻辑推导。此过程中,工作记忆(Working Memory)负责暂存中间变量,前额叶皮层负责监控逻辑冲突。
但现有记忆缺乏对“中间推理状态”的维护,往往只存结果不存过程。记忆系统必须支持任务分解,并具备双系统验证机制,能够存储“推理链条”而非仅仅是静态知识。
- 场景四:历史知识更新(冲突消解与再巩固)
当新读到的传记(“拿破仑输于情报失误”)与你原本的记忆(“拿破仑输于固执”)发生冲突时,大脑不会简单地覆盖旧数据,而是进行逻辑验证和情感加权。大脑会激活“记忆再巩固”机制,决定是修正旧记忆,还是将新信息作为一个新的分支版本存储。
向量库难以处理这种事实冲突,往往导致检索时出现相互矛盾的信息。所以必须具备冲突检测和记忆再巩固机制,支持知识的动态进化。
COLMA
基于上述需求,论文提出了 COLMA (Cognitive Layered Memory Architecture):
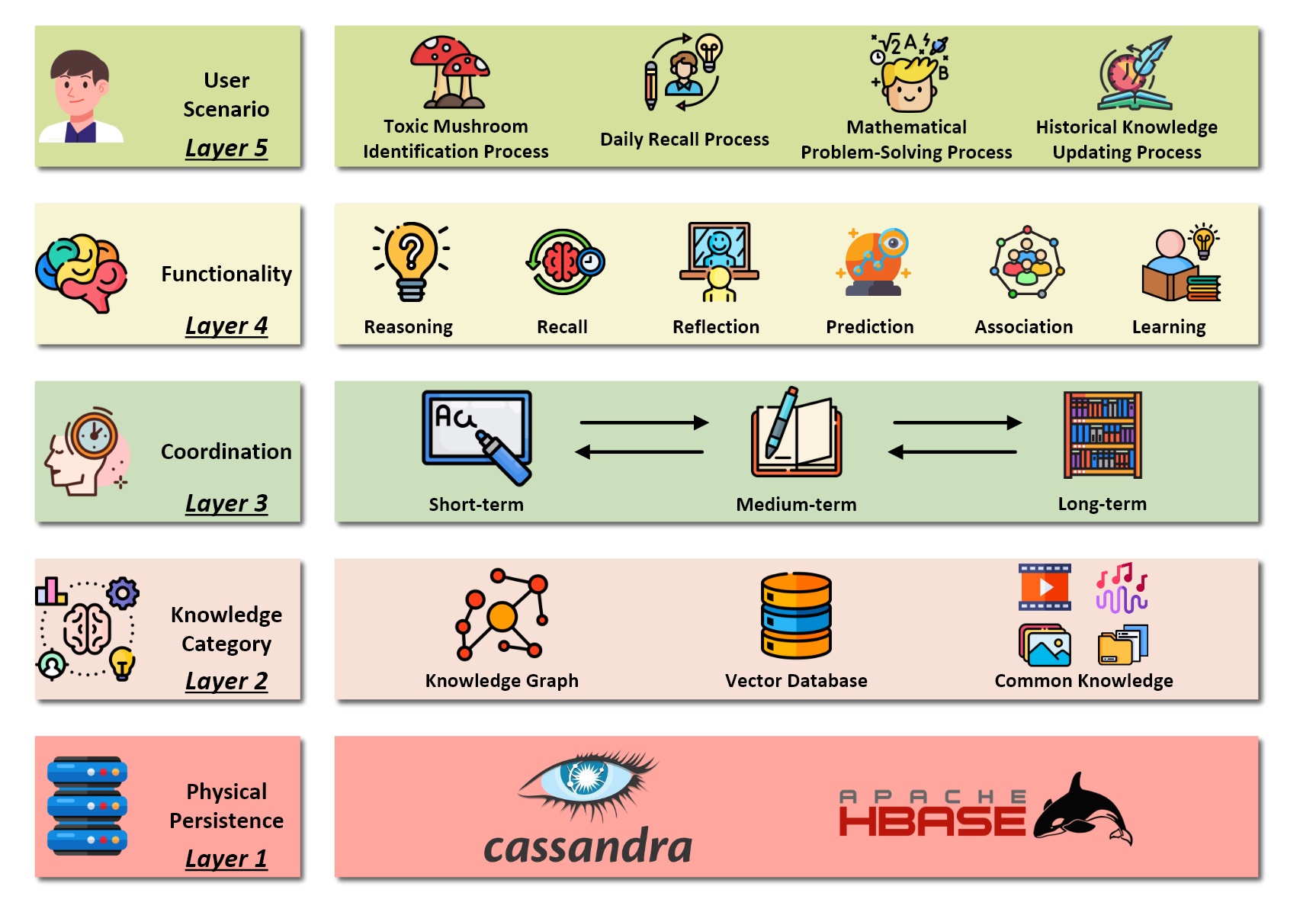
- Layer 1: 物理持久层 (Physical Persistence Layer)
使用 Apache Cassandra 或 HBase。不同于传统的关系型数据库,这一层利用分布式列式存储的高吞吐和 Schema-free 特性,为海量的多模态数据提供坚实的物理底座。它负责解决“存得下”和“写得快”的问题。
- Layer 2: 知识分类层 (Knowledge Category Layer)
异构数据统一封装。这是一个融合层。它打破了技术栈的壁垒,将知识图谱(结构化关系)、向量数据库(非结构化语义)和常识库统一在一个层面进行管理。无论是文本、图像向量还是逻辑实体,在此层都被视为可被索引的知识对象,解决了多模态数据割裂的问题。
- Layer 3: 协调层 (Coordination Layer)
这一层模拟海马体与新皮层的协同。这是架构的“大脑”。它负责管理短时记忆(Working Memory)、中时记忆和长时记忆之间的动态流转。正如海马体负责将短期经历固化为长期记忆,这一层决定了哪些信息值得被持久化,哪些应当被遗忘,实现了认知资源的优化配置。
- Layer 4: 功能层 (Functionality Layer)
提供具体的认知操作接口。这一层向上层暴露了推理 (Reasoning)、回忆 (Recall)、联想 (Association)、预测 (Prediction) 和 反思 (Reflection) 等高级能力。它让上层应用不再直接操作 CRUD 接口,而是调用类似“联想”这样的认知指令。
- Layer 5: 用户场景层 (User Scenario Layer)
应用场景对接。最顶层,直接对接具体的应用需求(如智能助手、决策代理)。它将业务逻辑翻译为对下层认知功能的调用。
个人碎碎念
可惜的是这篇论文没有代码,但个人看下来理论到工程也存在一些盲点。
首先是协调层的逻辑贫血问题。论文将协调层定义为模拟海马体功能的模块,负责管理短时记忆向长时记忆的流转。在论文的描述中,这是一个优雅的漏斗,但在真实的工程实现中,如果仅依靠简单的阈值(如访问频率或语义相似度)来决定记忆的去留,这个漏斗很快就会堵塞。如果没有复杂的清洗逻辑,大量的无效对话和冗余信息会被永久写入底层存储,导致存储成本爆炸且检索信噪比下降。所以我认为这里还需要一个做记忆整理的操作。
其次是被动性,因为数据库本身不会思考。论文隐含的交互模型是标准的请求-响应模式:用户提问,系统检索并存储。这也是当前 AI 记忆系统的痛点:被动性。人类的记忆整理往往发生在睡眠或空闲时,是一个主动的后台过程,数据会随着时间推移逐渐混乱,最终变得非常混乱。一个类脑的记忆系统,应该有办法主动唤醒,对碎片化的记忆进行合并和重组。
最后是搜索状态问题。个人认为在复杂的认知任务中,功能之间存在严格的时序依赖和状态共享。例如,往往是先回忆事实,再进行逻辑推导,最后才进行反思修正。如果将它们拆解为无状态的接口,外部调用者就需要维护复杂的上下文状态。再比如说,如果针对同一个会话连续调用两次“反思”,第二次应当基于第一次的结果进行深化,而不是重头再来或者返回一样的结果。因此,功能层内部应该还需要维护认知任务的生命周期和中间状态。
重构
思考到上面的内容之后,我认为可以重新定义论文中说到的分层,特别是中间三层(持久层、分类层、协调层)的交互逻辑。
Layer 1: 物理持久层
这一层其实没什么好讨论的,用 Cassandra 还是 HBase 其实是一个工程问题,不过最重要的洞见是它必须存原始数据(论文中也提到生态知觉理论,Ecological Perception Theory,核心思想是环境刺激的直接特征直接形成了初始的知觉表征),也就是作为事实的唯一来源。因为之前许多实践着重于将大模型的处理结果放到这一层,然而经常丢失一部分细节。至于索引那必然是要存的,否则性能很差,不过这个索引并不是语义索引,而是一个性能索引,这就是数据库的事情了,我们不在此详细讨论。
不过很容易想到一个问题,全部都是原始数据的话,上下文会变得特别长,且不符合我们认知的逻辑。起码我们知道,分层记忆是必然的(比如说目前主要包括短期、中期、长期记忆)。所以,处理是必须的,原始数据也是必须的,怎么办?
我想到一种方法是血缘追踪 (Data Lineage)。例如说某条记忆进行重组、合并、分裂、概括等等操作之后,需要保留一个血缘关系,即用一个 prev 指针去指向原来的数据,并将原来的数据标为 dirty(或者 archived),也就是不会作为数据被搜索到,只能溯源。如果上层使用这条操作后的数据之后发现它过于概括(Hallucination 的一种),可以直接溯源找到原始数据,以求真伪或更细节的认知。但时间久了这条链也会变得过长,所以这里面可能还需要引入一定的定期压缩或快照机制,但这属于更后期的优化了。
Layer 2: 知识分类层
这一层在很多架构图中被画得花里胡哨,但如果剥离掉那些名词,在工程实现上它其实就是一个DAO层。
我不建议在这里做太多的“智能”处理。为什么?因为这一层的核心职责提供抽象原语。很多系统设计失败的原因,就是把业务逻辑下沉得太深,导致想改策略的时候改不动。所以我认为这一层应该做得“薄”一点,它只需要把底层那堆复杂的宽表、图数据库封装成大概几个简单的原子操作:
- 文字匹配搜索:最朴素的正则或关键词匹配,用于精确查找。
- 知识图谱遍历:给一个节点,查它的 N 跳邻居。
- 向量最近邻:给一个 Embedding,找 Top-K。
- 血缘溯源:这个在上面提到
这一层就是给上面的协调层递砖头的。它不需要知道“为什么要查这个”,它只需要保证“查得快、查得准”。把多模态的差异在这里抹平,对上层暴露统一的接口,这就足够了。
Layer 3: 协调层
这是我认为整篇论文最关键、但也最需要工程填坑的地方。论文里说这一层负责“动态流转”,听起来很美,但在代码里怎么写?如果只是写几个 if (access_count < 5) move_to_long_term() 这样的阈值判断,那这个系统就太“薄”了,根本撑不起复杂的认知任务。
我认为协调层的本质不应该是简单的流转,而应该是记忆治理。目前的 AI Memory 系统最大的问题是“只进不出”和“被动响应”,时间一长,垃圾数据堆积如山。
所以,这一层必须具备类似 ETL 的能力,它需要主动地去做几件事:
- 同类合并:发现三条记忆都在说同一件事,就把它们由三个点合成一个点。
- 去冲突:新记忆说拿破仑高,旧记忆说拿破仑矮,这时候需要基于置信度去做冲突消解,而不是简单的覆盖。
- 垃圾回收:那些长期没用且与其他节点断连的孤立记忆,该清理就清理。包括上面说到的长链条血缘回溯。
谁来触发这些动作? 肯定不能只靠用户请求。我觉得起码要有三种触发器:
- 事件触发:上一次操作发现数据脏了,异步写个任务到队列里,后台慢慢修。
- 时间触发:像人睡觉一样,系统闲的时候,Cron Job 起来扫一遍,把碎片化的记忆整理一下。
- 阈值触发:当检索失败率飙升或者幻觉严重时,强制触发一次深度整理。这里面就包括之前的链长,或者说这个类型应该叫“系统事件”。
Layer 4: 功能层
到了这一层,其实就是面向大模型的 硬封装 了。论文里列了推理、回忆、联想、预测、反思这些功能,但在实际调用中,你不能指望外部调用者来维护这些功能之间的状态。
这里最容易被忽视的是序列关系。
比如,“先反思,再预测”。如果你直接调两次接口,第一次反思完了,第二次预测的时候,系统怎么知道你刚才反思了什么?难道要把反思的结果再传一遍?这太低效了。
所以这一层内部必须维护一个Session 级的状态机。
- 如果传入的是同一个
session_id,系统应该知道当前上下文已经走到了“反思完成”的状态。 - 这时候再调“预测”,它应该直接利用缓存中的反思结果,或者基于该状态继续推进。
- 如果我不想要上次的结果,我应该显式地开启新 Session。
这一层存在的意义,就是屏蔽掉下面那些复杂的血缘追踪、索引查询、ETL 治理,给大模型提供一个干净、有状态的认知接口。外部看起来是在调函数,内部其实是在跑一个复杂的认知工作流。